06 Mar Vérification des conditions de validité
Dans cet article, nous décrivons leurs conditions d’application, ainsi que la manière dont elles sont vérifiées par pvalue.io
Si par exemple on souhaite expliquer la probabilité de naître du sexe masculin en fonction du régime alimentaire, Y est le sexe masculin, et X le régime alimentaire).
Multicolinéarité
Les variables X ne doivent pas être dépendantes les unes des autres. En présence d’une multicolinéarité, l’estimation des coefficients, l’écart-type et les petits p ne sont pas corrects. Il est donc indispensable de la détecter à l’aide de méthodes plus ou moins sophistiquée.
Pour cela, le logiciel utilise un algorithme itératif basé sur le « Variance Inflation Factor » (le VIF).
Tant qu’il existe une variable ayant un VIF supérieur à 5, l’utilisateur est notifié de la présence d’une multicolinéarité et est invité à supprimer cette variable.
Régression linéaire
La régression linéaire a pour prérequis :
- Une relation linéaire entre la variable Y et chacune des variables quantitatives X. Pvalue.io affiche la courbe qui explique au mieux la relation entre les deux variables, tout en ajustant sur les autres variables explicatives (on appelle ce type de courbe une spline).
Lorsque ce prérequis n’est pas respecté, pvalue.io propose de transformer X : en sélectionnant des points sur la courbe, en utilisant des seuils donnés dans la littérature, ou bien par tercile, quartile et quintile.
Par exemple, sur la figure ci-après, la courbe est linéaire entre 25 et 45. Avant 25, il y a très peu d’observations, c’est pourquoi l’intervalle de confiance est très large; et après 45, la droite change de pente et devient presque horizontale. S’il n’existe pas d’arguments pour un autre type de découpage, il faudrait donc sélectionner le point 45 sur la courbe, ce qui transformerait la variable quantitative en variable catégorielle à 2 classes : ≤45, >45.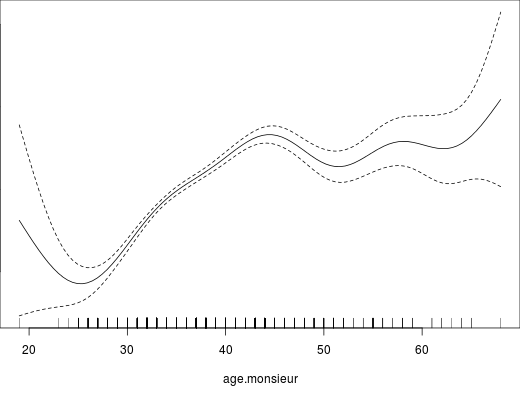
- Une normalité de la distribution résidus : cette normalité est vérifiée par un algorithme qui considère qu’une distribution proche de la distribution gaussienne est suffisante pour réaliser une régression linéaire (nous n’utilisons pas le test de Kolmogorov-Smirnov ou de Shapiro-Wilk). Pvalue.io vérifie que la moyenne est à peu près égale à la médiane et que la plupart de ses valeurs sont comprises entre le 25e et le 75e percentile. Si la normalité n’est pas respectée, pvalue.io effectue un bootstrap.
- Un nombre suffisant d’observations : Au moins 10 observations pour chaque variable X introduite dans le modèle; si X est catégorielle, et N le nombre de catégories différentes possibles, cela compte pour N-1 variables supplémentaires. L’utilisateur est donc invité à réduire le nombre de variables explicatives si le nombre d’observations est insuffisant.
- L’homoscédatiscité des résidus : pvalue.io vérifie que la variance des résidus est à peu près constante selon la valeur prédite.
- Une indépendance des résidus : cette condition ne peut être vérifiée de manière automatique. On admet généralement qu’elle est vérifiée en l’absence de mesures répétées dans le temps, si les autres conditions d’applications sont respectées,
En présence d’une hétéroscédaticité ou d’une analyse sur mesures répétées dans le temps, une expertise statistique est indispensable.
Régression logistique
La régression logistique nécessite :
- Une relation linéaire entre le logit (\(\ln \frac{p}{1-p}\)) de la variable Y et toutes les variables quantitatives X; pvalue.io propose la même approche que pour la régression linéaire.
- Un nombre suffisant d’observations : Au moins 10 observations pour lesquelles Y = 0 et Y = 1 pour chaque variable X introduite dans le modèle; si X est catégorielle, et N le nombre de catégories différentes possibles, cela compte pour N-1 variables supplémentaires. Il est tout à fait possible et même fréquent que vous n’ayez pas l’effectif suffisant, malgré un nombre important d’observations. C’est le cas notamment si vous avez peu d’observations pour lesquelles Y = 0 ou Y = 1, ou si vous avez des variables catégorielles avec un nombre élevé de classes.
L’utilisateur est donc invité à réduire le nombre de variables explicatives si le nombre d’observations est insuffisant.
Analyse de survie : Modèle de Cox
Le modèle de Cox nécessite :
- Une relation linéaire entre le logarithme du risque instantané et toutes les variables quantitatives X; pvalue.io propose la même approche que pour les régressions linéaire et logistique : c’est l’hypothèse de log-linéarité.
- Que le Hazard Ratio associé à la variable varie pas au cours du temps : c’est l’hypothèse des risques proportionnels
- Un nombre suffisant d’observations : Au moins 10 observations pour lesquelles Y = 0 et Y = 1 pour chaque variable X introduite dans le modèle; si X est catégorielle, et N le nombre de valeurs différentes possibles, cela compte pour N-1 variables supplémentaires. L’utilisateur est donc invité à réduire le nombre de variables explicatives si le nombre d’observations est insuffisant.
Aucun commentaire